億信華辰
連續(xù)3年穩(wěn)坐商務(wù)智能應(yīng)用榜首
與此同時(shí),億信華辰在數(shù)據(jù)治理領(lǐng)域榮登五強(qiáng)
關(guān)于數(shù)據(jù)分析,你需要知道的ETL基礎(chǔ)知識(shí)
時(shí)間:2022-06-09來(lái)源:小億瀏覽數(shù):710次
信息是現(xiàn)代企業(yè)的重要資源,是企業(yè)運(yùn)用科學(xué)管理、決策分析的基礎(chǔ)。據(jù)統(tǒng)計(jì),數(shù)據(jù)量每經(jīng)過(guò)2-3年時(shí)間就會(huì)成倍增長(zhǎng),這些數(shù)據(jù)蘊(yùn)含著巨大的商業(yè)價(jià)值,而企業(yè)所關(guān)注的通常只占總數(shù)據(jù)量的2%~4%左右。因此,企業(yè)仍然沒(méi)有最大化地利用已存在的數(shù)據(jù)資源,以至于浪費(fèi)了更多的時(shí)間和資金,也失去制定關(guān)鍵商業(yè)決策的最佳契機(jī)。
 于是,企業(yè)如何通過(guò)各種技術(shù)手段,并把數(shù)據(jù)轉(zhuǎn)換為信息、知識(shí),已經(jīng)成了提高其核心競(jìng)爭(zhēng)力的關(guān)鍵,其中的數(shù)據(jù)處理在大數(shù)據(jù)的生態(tài)中始終處于不可缺少的地位,因?yàn)閿?shù)據(jù)處理的時(shí)效性,準(zhǔn)確性直接影響數(shù)據(jù)的分析與挖掘,分析的最終結(jié)果影響業(yè)務(wù)的營(yíng)銷(xiāo)與收入。
今天我們就來(lái)說(shuō)說(shuō)一種重要的數(shù)據(jù)處理手段ETL(Extract-Transform-Load)。
01、ETL發(fā)展的歷史背景
隨著企業(yè)的發(fā)展,各業(yè)務(wù)線、產(chǎn)品線、部門(mén)都會(huì)承建各種信息化系統(tǒng)方便開(kāi)展自己的業(yè)務(wù)。隨著信息化建設(shè)的不斷深入,由于業(yè)務(wù)系統(tǒng)之間各自為政、相互獨(dú)立造成的數(shù)據(jù)孤島”現(xiàn)象尤為普遍,業(yè)務(wù)不集成、流程不互通、數(shù)據(jù)不共享。這給企業(yè)進(jìn)行數(shù)據(jù)的分析利用、報(bào)表開(kāi)發(fā)、分析挖掘等帶來(lái)了巨大困難。
在此情況下,為了實(shí)現(xiàn)企業(yè)全局?jǐn)?shù)據(jù)的系統(tǒng)化運(yùn)作管理(信息孤島、數(shù)據(jù)統(tǒng)計(jì)、數(shù)據(jù)分析、數(shù)據(jù)挖掘) ,為DSS(決策支持系統(tǒng))、BI(商務(wù)智能)、經(jīng)營(yíng)分析系統(tǒng)等深度開(kāi)發(fā)應(yīng)用奠定基礎(chǔ),挖掘數(shù)據(jù)價(jià)值 ,企業(yè)會(huì)開(kāi)始著手建立數(shù)據(jù)倉(cāng)庫(kù),數(shù)據(jù)中臺(tái)。將相互分離的業(yè)務(wù)系統(tǒng)的數(shù)據(jù)源整合在一起,建立一個(gè)統(tǒng)一的數(shù)據(jù)采集、處理、存儲(chǔ)、分發(fā)、共享中心,從而使公司的成員能夠從不同業(yè)務(wù)部門(mén)查看綜合數(shù)據(jù),而這個(gè)過(guò)程中使用的數(shù)據(jù)處理方法之一就是ETL。
ETL是數(shù)據(jù)中心建設(shè)、BI分析項(xiàng)目中不可或缺的環(huán)節(jié)。各個(gè)業(yè)務(wù)系統(tǒng)中分布的、異構(gòu)的數(shù)據(jù)源,經(jīng)過(guò)ETL過(guò)程的數(shù)據(jù)抽取、轉(zhuǎn)換,最終存儲(chǔ)到目標(biāo)數(shù)據(jù)庫(kù)或者數(shù)據(jù)倉(cāng)庫(kù),為上層BI數(shù)據(jù)分析,或其他業(yè)務(wù)功能做數(shù)據(jù)支撐。
02、什么是ETL?
ETL,Extract-Transform-Load的縮寫(xiě),是將業(yè)務(wù)系統(tǒng)的數(shù)據(jù)經(jīng)過(guò)抽取、清洗轉(zhuǎn)換之后加載到數(shù)據(jù)倉(cāng)庫(kù)的過(guò)程。ETL是數(shù)據(jù)集成的第一步,也是構(gòu)建數(shù)據(jù)倉(cāng)庫(kù)最重要的步驟,目的是將企業(yè)中的分散、零亂、標(biāo)準(zhǔn)不統(tǒng)一的數(shù)據(jù)整合到一起,為企業(yè)的決策提供分析依據(jù)。ETL一詞較常用在數(shù)據(jù)倉(cāng)庫(kù),但其對(duì)象并不限于數(shù)據(jù)倉(cāng)庫(kù)。
于是,企業(yè)如何通過(guò)各種技術(shù)手段,并把數(shù)據(jù)轉(zhuǎn)換為信息、知識(shí),已經(jīng)成了提高其核心競(jìng)爭(zhēng)力的關(guān)鍵,其中的數(shù)據(jù)處理在大數(shù)據(jù)的生態(tài)中始終處于不可缺少的地位,因?yàn)閿?shù)據(jù)處理的時(shí)效性,準(zhǔn)確性直接影響數(shù)據(jù)的分析與挖掘,分析的最終結(jié)果影響業(yè)務(wù)的營(yíng)銷(xiāo)與收入。
今天我們就來(lái)說(shuō)說(shuō)一種重要的數(shù)據(jù)處理手段ETL(Extract-Transform-Load)。
01、ETL發(fā)展的歷史背景
隨著企業(yè)的發(fā)展,各業(yè)務(wù)線、產(chǎn)品線、部門(mén)都會(huì)承建各種信息化系統(tǒng)方便開(kāi)展自己的業(yè)務(wù)。隨著信息化建設(shè)的不斷深入,由于業(yè)務(wù)系統(tǒng)之間各自為政、相互獨(dú)立造成的數(shù)據(jù)孤島”現(xiàn)象尤為普遍,業(yè)務(wù)不集成、流程不互通、數(shù)據(jù)不共享。這給企業(yè)進(jìn)行數(shù)據(jù)的分析利用、報(bào)表開(kāi)發(fā)、分析挖掘等帶來(lái)了巨大困難。
在此情況下,為了實(shí)現(xiàn)企業(yè)全局?jǐn)?shù)據(jù)的系統(tǒng)化運(yùn)作管理(信息孤島、數(shù)據(jù)統(tǒng)計(jì)、數(shù)據(jù)分析、數(shù)據(jù)挖掘) ,為DSS(決策支持系統(tǒng))、BI(商務(wù)智能)、經(jīng)營(yíng)分析系統(tǒng)等深度開(kāi)發(fā)應(yīng)用奠定基礎(chǔ),挖掘數(shù)據(jù)價(jià)值 ,企業(yè)會(huì)開(kāi)始著手建立數(shù)據(jù)倉(cāng)庫(kù),數(shù)據(jù)中臺(tái)。將相互分離的業(yè)務(wù)系統(tǒng)的數(shù)據(jù)源整合在一起,建立一個(gè)統(tǒng)一的數(shù)據(jù)采集、處理、存儲(chǔ)、分發(fā)、共享中心,從而使公司的成員能夠從不同業(yè)務(wù)部門(mén)查看綜合數(shù)據(jù),而這個(gè)過(guò)程中使用的數(shù)據(jù)處理方法之一就是ETL。
ETL是數(shù)據(jù)中心建設(shè)、BI分析項(xiàng)目中不可或缺的環(huán)節(jié)。各個(gè)業(yè)務(wù)系統(tǒng)中分布的、異構(gòu)的數(shù)據(jù)源,經(jīng)過(guò)ETL過(guò)程的數(shù)據(jù)抽取、轉(zhuǎn)換,最終存儲(chǔ)到目標(biāo)數(shù)據(jù)庫(kù)或者數(shù)據(jù)倉(cāng)庫(kù),為上層BI數(shù)據(jù)分析,或其他業(yè)務(wù)功能做數(shù)據(jù)支撐。
02、什么是ETL?
ETL,Extract-Transform-Load的縮寫(xiě),是將業(yè)務(wù)系統(tǒng)的數(shù)據(jù)經(jīng)過(guò)抽取、清洗轉(zhuǎn)換之后加載到數(shù)據(jù)倉(cāng)庫(kù)的過(guò)程。ETL是數(shù)據(jù)集成的第一步,也是構(gòu)建數(shù)據(jù)倉(cāng)庫(kù)最重要的步驟,目的是將企業(yè)中的分散、零亂、標(biāo)準(zhǔn)不統(tǒng)一的數(shù)據(jù)整合到一起,為企業(yè)的決策提供分析依據(jù)。ETL一詞較常用在數(shù)據(jù)倉(cāng)庫(kù),但其對(duì)象并不限于數(shù)據(jù)倉(cāng)庫(kù)。
 舉個(gè)例子,某電商公司分析人員根據(jù)訂單數(shù)據(jù)進(jìn)行用戶特征分析。這時(shí)需要基于訂單數(shù)據(jù),計(jì)算一些相應(yīng)的分析指標(biāo),如每個(gè)用戶的消費(fèi)頻次,銷(xiāo)售額最大的單品,用戶復(fù)購(gòu)時(shí)間間隔等,這些指標(biāo)都要通過(guò)計(jì)算轉(zhuǎn)換得到。
03、ETL的流程
ETL如同它代表的三個(gè)英文單詞,涉及三個(gè)獨(dú)立的過(guò)程:抽取、轉(zhuǎn)換和加載。工作流程往往作為一個(gè)正在進(jìn)行的過(guò)程來(lái)實(shí)現(xiàn),各模塊可靈活進(jìn)行組合,形成ETL處理流程。
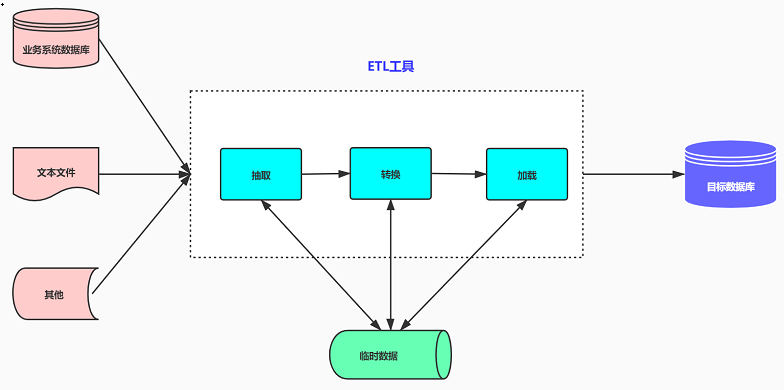
1.數(shù)據(jù)抽取
數(shù)據(jù)抽取指的是從不同的網(wǎng)絡(luò)、不同的操作平臺(tái)、不同的數(shù)據(jù)庫(kù)和數(shù)據(jù)格式、不同的應(yīng)用中抽取數(shù)據(jù)的過(guò)程。目標(biāo)源可能包括ERP、CRM和其他企業(yè)系統(tǒng),以及來(lái)自第三方源的數(shù)據(jù)。
舉個(gè)例子,某電商公司分析人員根據(jù)訂單數(shù)據(jù)進(jìn)行用戶特征分析。這時(shí)需要基于訂單數(shù)據(jù),計(jì)算一些相應(yīng)的分析指標(biāo),如每個(gè)用戶的消費(fèi)頻次,銷(xiāo)售額最大的單品,用戶復(fù)購(gòu)時(shí)間間隔等,這些指標(biāo)都要通過(guò)計(jì)算轉(zhuǎn)換得到。
03、ETL的流程
ETL如同它代表的三個(gè)英文單詞,涉及三個(gè)獨(dú)立的過(guò)程:抽取、轉(zhuǎn)換和加載。工作流程往往作為一個(gè)正在進(jìn)行的過(guò)程來(lái)實(shí)現(xiàn),各模塊可靈活進(jìn)行組合,形成ETL處理流程。
1.數(shù)據(jù)抽取
數(shù)據(jù)抽取指的是從不同的網(wǎng)絡(luò)、不同的操作平臺(tái)、不同的數(shù)據(jù)庫(kù)和數(shù)據(jù)格式、不同的應(yīng)用中抽取數(shù)據(jù)的過(guò)程。目標(biāo)源可能包括ERP、CRM和其他企業(yè)系統(tǒng),以及來(lái)自第三方源的數(shù)據(jù)。
 不同的系統(tǒng)傾向于使用不同的數(shù)據(jù)格式,在這個(gè)過(guò)程中,首先需要結(jié)合業(yè)務(wù)需求確定抽取的字段,形成一張公共需求表頭,并且數(shù)據(jù)庫(kù)字段也應(yīng)與這些需求字段形成一一映射關(guān)系。這樣通過(guò)數(shù)據(jù)抽取所得到的數(shù)據(jù)都具有統(tǒng)一、規(guī)整的字段內(nèi)容,為后續(xù)的數(shù)據(jù)轉(zhuǎn)換和加載提供基礎(chǔ),具體步驟如下:
①確定數(shù)據(jù)源,需要確定從哪些源系統(tǒng)進(jìn)行數(shù)據(jù)抽取
②定義數(shù)據(jù)接口,對(duì)每個(gè)源文件及系統(tǒng)的每個(gè)字段進(jìn)行詳細(xì)說(shuō)明
③確定數(shù)據(jù)抽取的方法:是主動(dòng)抽取還是由源系統(tǒng)推送?是增量抽取還是全量抽取?是按照每日抽取還是按照每月抽取?
2.數(shù)據(jù)轉(zhuǎn)換
數(shù)據(jù)轉(zhuǎn)換實(shí)際上還包含了數(shù)據(jù)清洗的工作,需要根據(jù)業(yè)務(wù)規(guī)則對(duì)異常數(shù)據(jù)進(jìn)行清洗,主要將不完整數(shù)據(jù)、錯(cuò)誤數(shù)據(jù)、重復(fù)數(shù)據(jù)進(jìn)行處理,保證后續(xù)分析結(jié)果的準(zhǔn)確性。
數(shù)據(jù)轉(zhuǎn)換就是處理抽取上來(lái)的數(shù)據(jù)中存在的不一致的過(guò)程。數(shù)據(jù)轉(zhuǎn)換一般包括兩類(lèi):第一類(lèi):數(shù)據(jù)名稱(chēng)及格式的統(tǒng)一,即數(shù)據(jù)粒度轉(zhuǎn)換、商務(wù)規(guī)則計(jì)算以及統(tǒng)一的命名、數(shù)據(jù)格式、計(jì)量單位等;第二類(lèi):數(shù)據(jù)倉(cāng)庫(kù)中存在源數(shù)據(jù)庫(kù)中可能不存在的數(shù)據(jù),因此需要進(jìn)行字段的組合、分割或計(jì)算。主要涉及以下幾個(gè)方面:
①空值處理:可捕獲字段空值,進(jìn)行加載或替換為其他含義數(shù)據(jù),或數(shù)據(jù)分流問(wèn)題庫(kù)
②數(shù)據(jù)標(biāo)準(zhǔn):統(tǒng)一元數(shù)據(jù)、統(tǒng)一標(biāo)準(zhǔn)字段、統(tǒng)一字段類(lèi)型定義
③數(shù)據(jù)拆分:依據(jù)業(yè)務(wù)需求做數(shù)據(jù)拆分,如身份證號(hào),拆分區(qū)劃、出生日期、性別等
④數(shù)據(jù)驗(yàn)證:時(shí)間規(guī)則、業(yè)務(wù)規(guī)則、自定義規(guī)則
⑤數(shù)據(jù)替換:對(duì)于因業(yè)務(wù)因素,可實(shí)現(xiàn)無(wú)效數(shù)據(jù)、缺失數(shù)據(jù)的替換
⑥數(shù)據(jù)關(guān)聯(lián):關(guān)聯(lián)其他數(shù)據(jù)或數(shù)學(xué),保障數(shù)據(jù)完整性
3.數(shù)據(jù)加載
數(shù)據(jù)加載的主要任務(wù)是將經(jīng)過(guò)清洗后的干凈的數(shù)據(jù)集按照物理數(shù)據(jù)模型定義的表結(jié)構(gòu)裝入目標(biāo)數(shù)據(jù)倉(cāng)庫(kù)的數(shù)據(jù)表中,如果是全量方式則采用LOAD方式,如果是增量則根據(jù)業(yè)務(wù)規(guī)則MERGE進(jìn)數(shù)據(jù)庫(kù),并允許人工干預(yù),以及提供強(qiáng)大的錯(cuò)誤報(bào)告、系統(tǒng)日志、數(shù)據(jù)備份與恢復(fù)功能。整個(gè)操作過(guò)程往往要跨網(wǎng)絡(luò)、跨操作平臺(tái)。
在實(shí)際的工作中,數(shù)據(jù)加載需要結(jié)合使用的數(shù)據(jù)庫(kù)系統(tǒng)(Oracle、Mysql、Spark、Impala等),確定最優(yōu)的數(shù)據(jù)加載方案,節(jié)約CPU、硬盤(pán)IO和網(wǎng)絡(luò)傳輸資源。
04、ETL與ELT有什么區(qū)別?
不同的系統(tǒng)傾向于使用不同的數(shù)據(jù)格式,在這個(gè)過(guò)程中,首先需要結(jié)合業(yè)務(wù)需求確定抽取的字段,形成一張公共需求表頭,并且數(shù)據(jù)庫(kù)字段也應(yīng)與這些需求字段形成一一映射關(guān)系。這樣通過(guò)數(shù)據(jù)抽取所得到的數(shù)據(jù)都具有統(tǒng)一、規(guī)整的字段內(nèi)容,為后續(xù)的數(shù)據(jù)轉(zhuǎn)換和加載提供基礎(chǔ),具體步驟如下:
①確定數(shù)據(jù)源,需要確定從哪些源系統(tǒng)進(jìn)行數(shù)據(jù)抽取
②定義數(shù)據(jù)接口,對(duì)每個(gè)源文件及系統(tǒng)的每個(gè)字段進(jìn)行詳細(xì)說(shuō)明
③確定數(shù)據(jù)抽取的方法:是主動(dòng)抽取還是由源系統(tǒng)推送?是增量抽取還是全量抽取?是按照每日抽取還是按照每月抽取?
2.數(shù)據(jù)轉(zhuǎn)換
數(shù)據(jù)轉(zhuǎn)換實(shí)際上還包含了數(shù)據(jù)清洗的工作,需要根據(jù)業(yè)務(wù)規(guī)則對(duì)異常數(shù)據(jù)進(jìn)行清洗,主要將不完整數(shù)據(jù)、錯(cuò)誤數(shù)據(jù)、重復(fù)數(shù)據(jù)進(jìn)行處理,保證后續(xù)分析結(jié)果的準(zhǔn)確性。
數(shù)據(jù)轉(zhuǎn)換就是處理抽取上來(lái)的數(shù)據(jù)中存在的不一致的過(guò)程。數(shù)據(jù)轉(zhuǎn)換一般包括兩類(lèi):第一類(lèi):數(shù)據(jù)名稱(chēng)及格式的統(tǒng)一,即數(shù)據(jù)粒度轉(zhuǎn)換、商務(wù)規(guī)則計(jì)算以及統(tǒng)一的命名、數(shù)據(jù)格式、計(jì)量單位等;第二類(lèi):數(shù)據(jù)倉(cāng)庫(kù)中存在源數(shù)據(jù)庫(kù)中可能不存在的數(shù)據(jù),因此需要進(jìn)行字段的組合、分割或計(jì)算。主要涉及以下幾個(gè)方面:
①空值處理:可捕獲字段空值,進(jìn)行加載或替換為其他含義數(shù)據(jù),或數(shù)據(jù)分流問(wèn)題庫(kù)
②數(shù)據(jù)標(biāo)準(zhǔn):統(tǒng)一元數(shù)據(jù)、統(tǒng)一標(biāo)準(zhǔn)字段、統(tǒng)一字段類(lèi)型定義
③數(shù)據(jù)拆分:依據(jù)業(yè)務(wù)需求做數(shù)據(jù)拆分,如身份證號(hào),拆分區(qū)劃、出生日期、性別等
④數(shù)據(jù)驗(yàn)證:時(shí)間規(guī)則、業(yè)務(wù)規(guī)則、自定義規(guī)則
⑤數(shù)據(jù)替換:對(duì)于因業(yè)務(wù)因素,可實(shí)現(xiàn)無(wú)效數(shù)據(jù)、缺失數(shù)據(jù)的替換
⑥數(shù)據(jù)關(guān)聯(lián):關(guān)聯(lián)其他數(shù)據(jù)或數(shù)學(xué),保障數(shù)據(jù)完整性
3.數(shù)據(jù)加載
數(shù)據(jù)加載的主要任務(wù)是將經(jīng)過(guò)清洗后的干凈的數(shù)據(jù)集按照物理數(shù)據(jù)模型定義的表結(jié)構(gòu)裝入目標(biāo)數(shù)據(jù)倉(cāng)庫(kù)的數(shù)據(jù)表中,如果是全量方式則采用LOAD方式,如果是增量則根據(jù)業(yè)務(wù)規(guī)則MERGE進(jìn)數(shù)據(jù)庫(kù),并允許人工干預(yù),以及提供強(qiáng)大的錯(cuò)誤報(bào)告、系統(tǒng)日志、數(shù)據(jù)備份與恢復(fù)功能。整個(gè)操作過(guò)程往往要跨網(wǎng)絡(luò)、跨操作平臺(tái)。
在實(shí)際的工作中,數(shù)據(jù)加載需要結(jié)合使用的數(shù)據(jù)庫(kù)系統(tǒng)(Oracle、Mysql、Spark、Impala等),確定最優(yōu)的數(shù)據(jù)加載方案,節(jié)約CPU、硬盤(pán)IO和網(wǎng)絡(luò)傳輸資源。
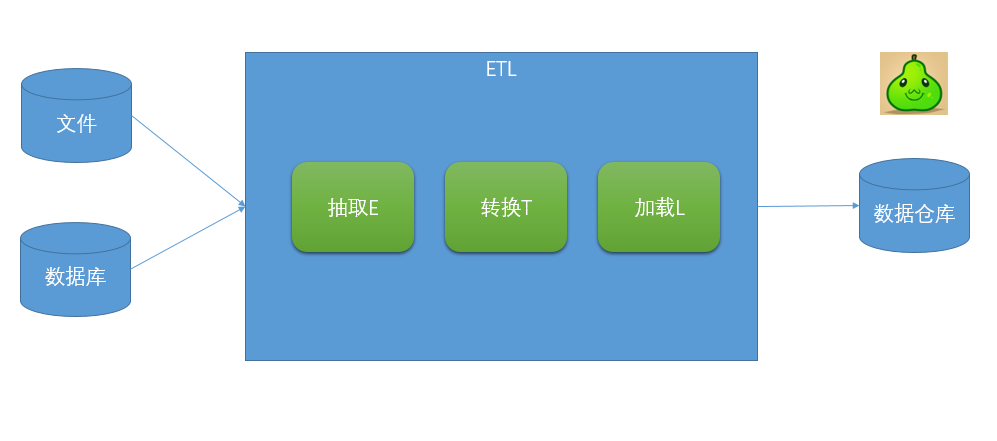
04、ETL與ELT有什么區(qū)別?
 ETL架構(gòu)按其字面含義理解就是按照E-T-L這個(gè)順序流程進(jìn)行處理的架構(gòu):先抽取、然后轉(zhuǎn)換、完成后加載到目標(biāo)數(shù)據(jù)庫(kù)中。
在ETL架構(gòu)中,數(shù)據(jù)的流向是從源數(shù)據(jù)流到ETL工具,ETL工具是一個(gè)單獨(dú)的數(shù)據(jù)處理引擎,一般會(huì)在單獨(dú)的硬件服務(wù)器上,實(shí)現(xiàn)所有數(shù)據(jù)轉(zhuǎn)化的工作,然后將數(shù)據(jù)加載到目標(biāo)數(shù)據(jù)倉(cāng)庫(kù)中。如果要增加整個(gè)ETL過(guò)程的效率,則只能增強(qiáng)ETL工具服務(wù)器的配置,優(yōu)化系統(tǒng)處理流程(一般可調(diào)的東西非常少)。
ETL架構(gòu)按其字面含義理解就是按照E-T-L這個(gè)順序流程進(jìn)行處理的架構(gòu):先抽取、然后轉(zhuǎn)換、完成后加載到目標(biāo)數(shù)據(jù)庫(kù)中。
在ETL架構(gòu)中,數(shù)據(jù)的流向是從源數(shù)據(jù)流到ETL工具,ETL工具是一個(gè)單獨(dú)的數(shù)據(jù)處理引擎,一般會(huì)在單獨(dú)的硬件服務(wù)器上,實(shí)現(xiàn)所有數(shù)據(jù)轉(zhuǎn)化的工作,然后將數(shù)據(jù)加載到目標(biāo)數(shù)據(jù)倉(cāng)庫(kù)中。如果要增加整個(gè)ETL過(guò)程的效率,則只能增強(qiáng)ETL工具服務(wù)器的配置,優(yōu)化系統(tǒng)處理流程(一般可調(diào)的東西非常少)。
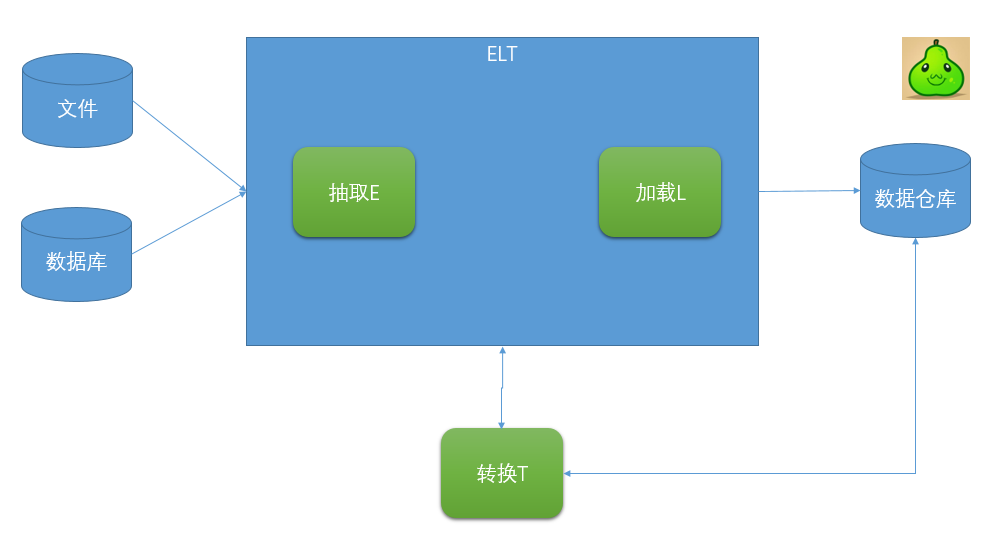 ELT架構(gòu)則把“L”這一步工作提前到“T”之前來(lái)完成:先抽取、然后加載到目標(biāo)數(shù)據(jù)庫(kù)中、在目標(biāo)數(shù)據(jù)庫(kù)中完成轉(zhuǎn)換操作。在ELT架構(gòu)中,ELT只負(fù)責(zé)提供圖形化的界面來(lái)設(shè)計(jì)業(yè)務(wù)規(guī)則,數(shù)據(jù)的整個(gè)加工過(guò)程都在目標(biāo)和源的數(shù)據(jù)庫(kù)之間流動(dòng),ELT協(xié)調(diào)相關(guān)的數(shù)據(jù)庫(kù)系統(tǒng)來(lái)執(zhí)行相關(guān)的應(yīng)用,數(shù)據(jù)加工過(guò)程既可以在源數(shù)據(jù)庫(kù)端執(zhí)行,也可以在目標(biāo)數(shù)據(jù)倉(cāng)庫(kù)端執(zhí)行(主要取決于系統(tǒng)的架構(gòu)設(shè)計(jì)和數(shù)據(jù)屬性)。當(dāng)ETL過(guò)程需要提高效率,則可以通過(guò)對(duì)相關(guān)數(shù)據(jù)庫(kù)進(jìn)行調(diào)優(yōu),或者改變執(zhí)行加工的服務(wù)器就可以達(dá)到。
ELT架構(gòu)的特殊優(yōu)勢(shì):①ELT主要通過(guò)數(shù)據(jù)庫(kù)引擎來(lái)實(shí)現(xiàn)系統(tǒng)的可擴(kuò)展性;②ELT可以保持所有的數(shù)據(jù)始終在數(shù)據(jù)庫(kù)當(dāng)中,避免數(shù)據(jù)的加載和導(dǎo)出,從而保證效率,提高系統(tǒng)的可監(jiān)控性;③ELT可以根據(jù)數(shù)據(jù)的分布情況進(jìn)行并行處理優(yōu)化,并可以利用數(shù)據(jù)庫(kù)的固有功能優(yōu)化磁盤(pán)I/O;④ELT的可擴(kuò)展性取決于數(shù)據(jù)庫(kù)引擎和其硬件服務(wù)器的可擴(kuò)展性;⑤通過(guò)對(duì)相關(guān)數(shù)據(jù)庫(kù)進(jìn)行性能調(diào)優(yōu),ELT過(guò)程獲得3到4倍的效率提升一般不是特別困難。
(1)當(dāng)您想要執(zhí)行復(fù)雜的計(jì)算時(shí),ETL工具比數(shù)據(jù)倉(cāng)庫(kù)或數(shù)據(jù)池更有效
(2)如果要在加載到目標(biāo)存儲(chǔ)之前進(jìn)行大量數(shù)據(jù)清理。ETL是一種更好的解決方案,因?yàn)槟粫?huì)將不需要的數(shù)據(jù)移動(dòng)到目標(biāo)。
(3)當(dāng)您僅使用結(jié)構(gòu)化數(shù)據(jù)或傳統(tǒng)結(jié)構(gòu)化數(shù)據(jù)倉(cāng)庫(kù)時(shí)。ETL工具通常最有效地將結(jié)構(gòu)化數(shù)據(jù)從一個(gè)環(huán)境移動(dòng)到另一個(gè)環(huán)境。
(4)當(dāng)你想要擴(kuò)展補(bǔ)充數(shù)據(jù)時(shí)。如果要在將數(shù)據(jù)移動(dòng)到目標(biāo)存儲(chǔ)時(shí)擴(kuò)展補(bǔ)充數(shù)據(jù),則需要使用ETL工具。例如,添加時(shí)間戳。
05、如何才能做好ETL?
1.數(shù)據(jù)抽取設(shè)計(jì)
數(shù)據(jù)的抽取需要在調(diào)研階段做大量工作,要搞清楚以下幾個(gè)問(wèn)題:數(shù)據(jù)是從幾個(gè)業(yè)務(wù)系統(tǒng)中來(lái)?各個(gè)業(yè)務(wù)系統(tǒng)的數(shù)據(jù)庫(kù)服務(wù)器運(yùn)行什么DBMS?是否存在手工數(shù)據(jù),手工數(shù)據(jù)量有多大?是否存在非結(jié)構(gòu)化的數(shù)據(jù)?等等類(lèi)似問(wèn)題,當(dāng)收集完這些信息之后進(jìn)行數(shù)據(jù)抽取的設(shè)計(jì)。常見(jiàn)的數(shù)據(jù)抽取設(shè)計(jì)方式有四種:
(1)與存放DW的數(shù)據(jù)庫(kù)系統(tǒng)相同的數(shù)據(jù)源處理方法
這一類(lèi)數(shù)源在設(shè)計(jì)比較容易,一般情況下,DBMS(包括SQLServer,Oracle)都會(huì)提供數(shù)據(jù)庫(kù)鏈接功能,在DW數(shù)據(jù)庫(kù)服務(wù)器和原業(yè)務(wù)系統(tǒng)之間建立直接的鏈接關(guān)系就可以寫(xiě)Select 語(yǔ)句直接訪問(wèn)。
(2)與DW數(shù)據(jù)庫(kù)系統(tǒng)不同的數(shù)據(jù)源的處理方法
這一類(lèi)數(shù)據(jù)源一般情況下也可以通過(guò)ODBC的方式建立數(shù)據(jù)庫(kù)鏈接,如SQL Server和Oracle之間。如果不能建立數(shù)據(jù)庫(kù)鏈接,可以有兩種方式完成,一種是通過(guò)工具將源數(shù)據(jù)導(dǎo)出成.txt或者是.xls文件,然后再將這些源系統(tǒng)文件導(dǎo)入到ODS中。另外一種方法通過(guò)程序接口來(lái)完成。
(3)對(duì)于文件類(lèi)型數(shù)據(jù)源(.txt,.xls)
可以培訓(xùn)業(yè)務(wù)人員利用數(shù)據(jù)庫(kù)工具將這些數(shù)據(jù)導(dǎo)入到指定的數(shù)據(jù)庫(kù),然后從指定的數(shù)據(jù)庫(kù)抽取。或者可以借助工具實(shí)現(xiàn),如SQL SERVER 2005 的SSIS服務(wù)的平面數(shù)據(jù)源和平面目標(biāo)等組件導(dǎo)入ODS中去。
(4)增量更新問(wèn)題
對(duì)于數(shù)據(jù)量大的系統(tǒng),必須考慮增量抽取。一般情況,業(yè)務(wù)系統(tǒng)會(huì)記錄業(yè)務(wù)發(fā)生的時(shí)間,可以用作增量的標(biāo)志,每次抽取之前首先判斷ODS中記錄最大的時(shí)間,然后根據(jù)這個(gè)時(shí)間去業(yè)務(wù)系統(tǒng)取大于這個(gè)時(shí)間的所有記錄。利用業(yè)務(wù)系統(tǒng)的時(shí)間戳,一般情況下,業(yè)務(wù)系統(tǒng)沒(méi)有或者部分有時(shí)間戳。
2.數(shù)據(jù)清洗處理規(guī)范
不符合要求的數(shù)據(jù)主要有不完成數(shù)據(jù)(缺失值)、錯(cuò)誤數(shù)據(jù)(異常值)、重復(fù)數(shù)據(jù)、不同類(lèi)型需歸一化處理數(shù)據(jù)幾類(lèi)。幾類(lèi)數(shù)據(jù)的處理方法如下:
缺失值:不完整的數(shù)據(jù),其特征是是一些應(yīng)該有的信息缺失,如供應(yīng)商的名稱(chēng),分公司的名稱(chēng),客戶的區(qū)域信息缺失、業(yè)務(wù)系統(tǒng)中主表與明細(xì)表不能匹配等。需要將這一類(lèi)數(shù)據(jù)過(guò)濾出來(lái),按缺失的內(nèi)容分別采取定(范圍)刪(字段)補(bǔ)(數(shù)據(jù))。
定范圍:哪些字段缺失,缺失范圍如何,缺失字段的重要性如何?刪字段:刪數(shù)據(jù)的判斷,a\對(duì)業(yè)務(wù)清晰的判斷,b\“有心殺賊,無(wú)力回天”缺失數(shù)據(jù)太多。這時(shí)候可以看看是否有其他數(shù)據(jù)可以彌補(bǔ)。補(bǔ)數(shù)據(jù):就是補(bǔ)充缺失值。這里有三種補(bǔ)數(shù)據(jù)的方式:A、業(yè)務(wù)知識(shí)驚訝填充;B、使用均值、中位數(shù)、眾數(shù)填充;C、使用其他渠道補(bǔ)充,如身份證前6位是地區(qū)=手機(jī)號(hào)歸屬地。補(bǔ)全后才寫(xiě)入數(shù)據(jù)倉(cāng)庫(kù)。
異常值:產(chǎn)生原因是業(yè)務(wù)系統(tǒng)不夠健全,在接收輸入后沒(méi)有進(jìn)行判斷直接寫(xiě)入后臺(tái)數(shù)據(jù)庫(kù)造成的,比如數(shù)值數(shù)據(jù)輸成全角數(shù)字字符、字符串?dāng)?shù)據(jù)后面有一個(gè)回車(chē)、日期格式不正確、日期越界等。這一類(lèi)數(shù)據(jù)也要分類(lèi),對(duì)于類(lèi)似于全角字符、數(shù)據(jù)前后有不面見(jiàn)字符的問(wèn)題只能寫(xiě)SQL的方式找出來(lái),然后要求客戶在業(yè)務(wù)系統(tǒng)修正之后抽取;日期格式不正確的或者是日期越界的這一類(lèi)錯(cuò)誤會(huì)導(dǎo)致ETL運(yùn)行失敗,這一類(lèi)錯(cuò)誤需要去業(yè)務(wù)系統(tǒng)數(shù)據(jù)庫(kù)用SQL的方式挑出來(lái),交給業(yè)務(wù)主管部門(mén)要求限期修正,修正之后再抽取。
重復(fù)數(shù)據(jù):特別是維表中比較常見(jiàn),將重復(fù)的數(shù)據(jù)的記錄所有字段導(dǎo)出來(lái),讓客戶確認(rèn)并整理。
數(shù)據(jù)歸一化:歸一化的問(wèn)題,就是將絕對(duì)數(shù)變成相對(duì)數(shù)的問(wèn)題。因?yàn)椴煌S度的絕對(duì)數(shù)是沒(méi)有可比性的,這時(shí)候需要將絕對(duì)數(shù)轉(zhuǎn)化成相對(duì)一個(gè)標(biāo)準(zhǔn)的相對(duì)數(shù)。那如何進(jìn)行歸一化處理呢?三種方式,A、最值歸一化、均值方差歸一化、非線性歸一化。
數(shù)據(jù)清洗是一個(gè)反復(fù)的過(guò)程,不可能在幾天內(nèi)完成,只有不斷的發(fā)現(xiàn)問(wèn)題,解決問(wèn)題。對(duì)于是否過(guò)濾、是否修正一般要求客戶確認(rèn);對(duì)于過(guò)濾掉的數(shù)據(jù),寫(xiě)入Excel文件或者將過(guò)濾數(shù)據(jù)寫(xiě)入數(shù)據(jù)表,在ETL開(kāi)發(fā)的初期可以每天向業(yè)務(wù)單位發(fā)送過(guò)濾數(shù)據(jù)的郵件,促使他們盡快的修正錯(cuò)誤,同時(shí)也可以作為將來(lái)驗(yàn)證數(shù)據(jù)的依據(jù)。數(shù)據(jù)清洗需要注意的是不要將有用的數(shù)據(jù)過(guò)濾掉了,對(duì)于每個(gè)過(guò)濾規(guī)則認(rèn)真進(jìn)行驗(yàn)證,并要用戶確認(rèn)才行。
3.數(shù)據(jù)轉(zhuǎn)換處理規(guī)范
數(shù)據(jù)轉(zhuǎn)換的任務(wù)主要是進(jìn)行不一致的數(shù)據(jù)轉(zhuǎn)換、數(shù)據(jù)粒度的轉(zhuǎn)換和一些商務(wù)規(guī)則的計(jì)算。
(1)不一致數(shù)據(jù)轉(zhuǎn)換,這個(gè)過(guò)程是一個(gè)整合的過(guò)程,將不同業(yè)務(wù)系統(tǒng)的相同類(lèi)型的數(shù)據(jù)統(tǒng)一,比如同一個(gè)供應(yīng)商在結(jié)算系統(tǒng)的編碼是XX0001,而在CRM中編碼是YY0001,這樣在抽取過(guò)來(lái)之后統(tǒng)一轉(zhuǎn)換成一個(gè)編碼。
(2)數(shù)據(jù)粒度的轉(zhuǎn)換,業(yè)務(wù)系統(tǒng)一般存儲(chǔ)非常明細(xì)的數(shù)據(jù),而數(shù)據(jù)倉(cāng)庫(kù)中的數(shù)據(jù)是用來(lái)分析的,不需要非常明細(xì)的數(shù)據(jù),會(huì)將業(yè)務(wù)系統(tǒng)數(shù)據(jù)按照數(shù)據(jù)倉(cāng)庫(kù)粒度進(jìn)行聚合。一般數(shù)據(jù)轉(zhuǎn)換有離散化和屬性構(gòu)造兩種方式。離散化主要分為簡(jiǎn)單離散、分桶離散、聚類(lèi)離散、回歸平滑四類(lèi),屬性構(gòu)造分為特征工程和隨意構(gòu)造后篩選。
(3)商務(wù)規(guī)則的計(jì)算,不同的企業(yè)有不同的業(yè)務(wù)規(guī)則,不同的數(shù)據(jù)指標(biāo),這些指標(biāo)有的時(shí)候不是簡(jiǎn)單的加加減減就能完成,這個(gè)時(shí)候需要在ETL中將這些數(shù)據(jù)指標(biāo)計(jì)算好了之后存儲(chǔ)在數(shù)據(jù)倉(cāng)庫(kù)中,供分析使用。
4.ETL日志與警告發(fā)送
(1)ETL日志
記錄日志的目的是隨時(shí)可以知道ETL運(yùn)行情況,如果出錯(cuò)了,出錯(cuò)在那里。
ETL日志分為三類(lèi)。①執(zhí)行過(guò)程日志,是在ETL執(zhí)行過(guò)程中每執(zhí)行一步的記錄,記錄每次運(yùn)行每一步驟的起始時(shí)間,影響了多少行數(shù)據(jù),流水賬形式。②是錯(cuò)誤日志,當(dāng)某個(gè)模塊出錯(cuò)的時(shí)候需要寫(xiě)錯(cuò)誤日志,記錄每次出錯(cuò)的時(shí)間,出錯(cuò)的模塊以及出錯(cuò)的信息等。③日志是總體日志,只記錄ETL開(kāi)始時(shí)間,結(jié)束時(shí)間是否成功信息。
如果使用ETL工具,工具會(huì)自動(dòng)產(chǎn)生一些日志,這一類(lèi)日志也可以作為ETL日志的一部分。
(2)警告發(fā)送
ETL出錯(cuò)了,不僅要寫(xiě)ETL出錯(cuò)日志而且要向系統(tǒng)管理員發(fā)送警告,發(fā)送警告的方式有多種,常用的就是給系統(tǒng)管理員發(fā)送郵件,并附上錯(cuò)誤信息,便于管理員排查。
06、小結(jié)
在這里涉及到ETL中,我們只要有一個(gè)清晰的認(rèn)識(shí),它不是想象中的簡(jiǎn)單一蹴而就,在實(shí)際的過(guò)程,你可以會(huì)遇到各種各樣的問(wèn)題,甚至是部門(mén)之間溝通的問(wèn)題。出現(xiàn)以上問(wèn)題時(shí),可以和團(tuán)隊(duì)小伙伴或者業(yè)務(wù)側(cè)一起制定解決方案,不斷完善,只有這樣才能保證我們的業(yè)務(wù)分析結(jié)果是準(zhǔn)確的,才能指導(dǎo)公司做出正確的決策。
ELT架構(gòu)則把“L”這一步工作提前到“T”之前來(lái)完成:先抽取、然后加載到目標(biāo)數(shù)據(jù)庫(kù)中、在目標(biāo)數(shù)據(jù)庫(kù)中完成轉(zhuǎn)換操作。在ELT架構(gòu)中,ELT只負(fù)責(zé)提供圖形化的界面來(lái)設(shè)計(jì)業(yè)務(wù)規(guī)則,數(shù)據(jù)的整個(gè)加工過(guò)程都在目標(biāo)和源的數(shù)據(jù)庫(kù)之間流動(dòng),ELT協(xié)調(diào)相關(guān)的數(shù)據(jù)庫(kù)系統(tǒng)來(lái)執(zhí)行相關(guān)的應(yīng)用,數(shù)據(jù)加工過(guò)程既可以在源數(shù)據(jù)庫(kù)端執(zhí)行,也可以在目標(biāo)數(shù)據(jù)倉(cāng)庫(kù)端執(zhí)行(主要取決于系統(tǒng)的架構(gòu)設(shè)計(jì)和數(shù)據(jù)屬性)。當(dāng)ETL過(guò)程需要提高效率,則可以通過(guò)對(duì)相關(guān)數(shù)據(jù)庫(kù)進(jìn)行調(diào)優(yōu),或者改變執(zhí)行加工的服務(wù)器就可以達(dá)到。
ELT架構(gòu)的特殊優(yōu)勢(shì):①ELT主要通過(guò)數(shù)據(jù)庫(kù)引擎來(lái)實(shí)現(xiàn)系統(tǒng)的可擴(kuò)展性;②ELT可以保持所有的數(shù)據(jù)始終在數(shù)據(jù)庫(kù)當(dāng)中,避免數(shù)據(jù)的加載和導(dǎo)出,從而保證效率,提高系統(tǒng)的可監(jiān)控性;③ELT可以根據(jù)數(shù)據(jù)的分布情況進(jìn)行并行處理優(yōu)化,并可以利用數(shù)據(jù)庫(kù)的固有功能優(yōu)化磁盤(pán)I/O;④ELT的可擴(kuò)展性取決于數(shù)據(jù)庫(kù)引擎和其硬件服務(wù)器的可擴(kuò)展性;⑤通過(guò)對(duì)相關(guān)數(shù)據(jù)庫(kù)進(jìn)行性能調(diào)優(yōu),ELT過(guò)程獲得3到4倍的效率提升一般不是特別困難。
(1)當(dāng)您想要執(zhí)行復(fù)雜的計(jì)算時(shí),ETL工具比數(shù)據(jù)倉(cāng)庫(kù)或數(shù)據(jù)池更有效
(2)如果要在加載到目標(biāo)存儲(chǔ)之前進(jìn)行大量數(shù)據(jù)清理。ETL是一種更好的解決方案,因?yàn)槟粫?huì)將不需要的數(shù)據(jù)移動(dòng)到目標(biāo)。
(3)當(dāng)您僅使用結(jié)構(gòu)化數(shù)據(jù)或傳統(tǒng)結(jié)構(gòu)化數(shù)據(jù)倉(cāng)庫(kù)時(shí)。ETL工具通常最有效地將結(jié)構(gòu)化數(shù)據(jù)從一個(gè)環(huán)境移動(dòng)到另一個(gè)環(huán)境。
(4)當(dāng)你想要擴(kuò)展補(bǔ)充數(shù)據(jù)時(shí)。如果要在將數(shù)據(jù)移動(dòng)到目標(biāo)存儲(chǔ)時(shí)擴(kuò)展補(bǔ)充數(shù)據(jù),則需要使用ETL工具。例如,添加時(shí)間戳。
05、如何才能做好ETL?
1.數(shù)據(jù)抽取設(shè)計(jì)
數(shù)據(jù)的抽取需要在調(diào)研階段做大量工作,要搞清楚以下幾個(gè)問(wèn)題:數(shù)據(jù)是從幾個(gè)業(yè)務(wù)系統(tǒng)中來(lái)?各個(gè)業(yè)務(wù)系統(tǒng)的數(shù)據(jù)庫(kù)服務(wù)器運(yùn)行什么DBMS?是否存在手工數(shù)據(jù),手工數(shù)據(jù)量有多大?是否存在非結(jié)構(gòu)化的數(shù)據(jù)?等等類(lèi)似問(wèn)題,當(dāng)收集完這些信息之后進(jìn)行數(shù)據(jù)抽取的設(shè)計(jì)。常見(jiàn)的數(shù)據(jù)抽取設(shè)計(jì)方式有四種:
(1)與存放DW的數(shù)據(jù)庫(kù)系統(tǒng)相同的數(shù)據(jù)源處理方法
這一類(lèi)數(shù)源在設(shè)計(jì)比較容易,一般情況下,DBMS(包括SQLServer,Oracle)都會(huì)提供數(shù)據(jù)庫(kù)鏈接功能,在DW數(shù)據(jù)庫(kù)服務(wù)器和原業(yè)務(wù)系統(tǒng)之間建立直接的鏈接關(guān)系就可以寫(xiě)Select 語(yǔ)句直接訪問(wèn)。
(2)與DW數(shù)據(jù)庫(kù)系統(tǒng)不同的數(shù)據(jù)源的處理方法
這一類(lèi)數(shù)據(jù)源一般情況下也可以通過(guò)ODBC的方式建立數(shù)據(jù)庫(kù)鏈接,如SQL Server和Oracle之間。如果不能建立數(shù)據(jù)庫(kù)鏈接,可以有兩種方式完成,一種是通過(guò)工具將源數(shù)據(jù)導(dǎo)出成.txt或者是.xls文件,然后再將這些源系統(tǒng)文件導(dǎo)入到ODS中。另外一種方法通過(guò)程序接口來(lái)完成。
(3)對(duì)于文件類(lèi)型數(shù)據(jù)源(.txt,.xls)
可以培訓(xùn)業(yè)務(wù)人員利用數(shù)據(jù)庫(kù)工具將這些數(shù)據(jù)導(dǎo)入到指定的數(shù)據(jù)庫(kù),然后從指定的數(shù)據(jù)庫(kù)抽取。或者可以借助工具實(shí)現(xiàn),如SQL SERVER 2005 的SSIS服務(wù)的平面數(shù)據(jù)源和平面目標(biāo)等組件導(dǎo)入ODS中去。
(4)增量更新問(wèn)題
對(duì)于數(shù)據(jù)量大的系統(tǒng),必須考慮增量抽取。一般情況,業(yè)務(wù)系統(tǒng)會(huì)記錄業(yè)務(wù)發(fā)生的時(shí)間,可以用作增量的標(biāo)志,每次抽取之前首先判斷ODS中記錄最大的時(shí)間,然后根據(jù)這個(gè)時(shí)間去業(yè)務(wù)系統(tǒng)取大于這個(gè)時(shí)間的所有記錄。利用業(yè)務(wù)系統(tǒng)的時(shí)間戳,一般情況下,業(yè)務(wù)系統(tǒng)沒(méi)有或者部分有時(shí)間戳。
2.數(shù)據(jù)清洗處理規(guī)范
不符合要求的數(shù)據(jù)主要有不完成數(shù)據(jù)(缺失值)、錯(cuò)誤數(shù)據(jù)(異常值)、重復(fù)數(shù)據(jù)、不同類(lèi)型需歸一化處理數(shù)據(jù)幾類(lèi)。幾類(lèi)數(shù)據(jù)的處理方法如下:
缺失值:不完整的數(shù)據(jù),其特征是是一些應(yīng)該有的信息缺失,如供應(yīng)商的名稱(chēng),分公司的名稱(chēng),客戶的區(qū)域信息缺失、業(yè)務(wù)系統(tǒng)中主表與明細(xì)表不能匹配等。需要將這一類(lèi)數(shù)據(jù)過(guò)濾出來(lái),按缺失的內(nèi)容分別采取定(范圍)刪(字段)補(bǔ)(數(shù)據(jù))。
定范圍:哪些字段缺失,缺失范圍如何,缺失字段的重要性如何?刪字段:刪數(shù)據(jù)的判斷,a\對(duì)業(yè)務(wù)清晰的判斷,b\“有心殺賊,無(wú)力回天”缺失數(shù)據(jù)太多。這時(shí)候可以看看是否有其他數(shù)據(jù)可以彌補(bǔ)。補(bǔ)數(shù)據(jù):就是補(bǔ)充缺失值。這里有三種補(bǔ)數(shù)據(jù)的方式:A、業(yè)務(wù)知識(shí)驚訝填充;B、使用均值、中位數(shù)、眾數(shù)填充;C、使用其他渠道補(bǔ)充,如身份證前6位是地區(qū)=手機(jī)號(hào)歸屬地。補(bǔ)全后才寫(xiě)入數(shù)據(jù)倉(cāng)庫(kù)。
異常值:產(chǎn)生原因是業(yè)務(wù)系統(tǒng)不夠健全,在接收輸入后沒(méi)有進(jìn)行判斷直接寫(xiě)入后臺(tái)數(shù)據(jù)庫(kù)造成的,比如數(shù)值數(shù)據(jù)輸成全角數(shù)字字符、字符串?dāng)?shù)據(jù)后面有一個(gè)回車(chē)、日期格式不正確、日期越界等。這一類(lèi)數(shù)據(jù)也要分類(lèi),對(duì)于類(lèi)似于全角字符、數(shù)據(jù)前后有不面見(jiàn)字符的問(wèn)題只能寫(xiě)SQL的方式找出來(lái),然后要求客戶在業(yè)務(wù)系統(tǒng)修正之后抽取;日期格式不正確的或者是日期越界的這一類(lèi)錯(cuò)誤會(huì)導(dǎo)致ETL運(yùn)行失敗,這一類(lèi)錯(cuò)誤需要去業(yè)務(wù)系統(tǒng)數(shù)據(jù)庫(kù)用SQL的方式挑出來(lái),交給業(yè)務(wù)主管部門(mén)要求限期修正,修正之后再抽取。
重復(fù)數(shù)據(jù):特別是維表中比較常見(jiàn),將重復(fù)的數(shù)據(jù)的記錄所有字段導(dǎo)出來(lái),讓客戶確認(rèn)并整理。
數(shù)據(jù)歸一化:歸一化的問(wèn)題,就是將絕對(duì)數(shù)變成相對(duì)數(shù)的問(wèn)題。因?yàn)椴煌S度的絕對(duì)數(shù)是沒(méi)有可比性的,這時(shí)候需要將絕對(duì)數(shù)轉(zhuǎn)化成相對(duì)一個(gè)標(biāo)準(zhǔn)的相對(duì)數(shù)。那如何進(jìn)行歸一化處理呢?三種方式,A、最值歸一化、均值方差歸一化、非線性歸一化。
數(shù)據(jù)清洗是一個(gè)反復(fù)的過(guò)程,不可能在幾天內(nèi)完成,只有不斷的發(fā)現(xiàn)問(wèn)題,解決問(wèn)題。對(duì)于是否過(guò)濾、是否修正一般要求客戶確認(rèn);對(duì)于過(guò)濾掉的數(shù)據(jù),寫(xiě)入Excel文件或者將過(guò)濾數(shù)據(jù)寫(xiě)入數(shù)據(jù)表,在ETL開(kāi)發(fā)的初期可以每天向業(yè)務(wù)單位發(fā)送過(guò)濾數(shù)據(jù)的郵件,促使他們盡快的修正錯(cuò)誤,同時(shí)也可以作為將來(lái)驗(yàn)證數(shù)據(jù)的依據(jù)。數(shù)據(jù)清洗需要注意的是不要將有用的數(shù)據(jù)過(guò)濾掉了,對(duì)于每個(gè)過(guò)濾規(guī)則認(rèn)真進(jìn)行驗(yàn)證,并要用戶確認(rèn)才行。
3.數(shù)據(jù)轉(zhuǎn)換處理規(guī)范
數(shù)據(jù)轉(zhuǎn)換的任務(wù)主要是進(jìn)行不一致的數(shù)據(jù)轉(zhuǎn)換、數(shù)據(jù)粒度的轉(zhuǎn)換和一些商務(wù)規(guī)則的計(jì)算。
(1)不一致數(shù)據(jù)轉(zhuǎn)換,這個(gè)過(guò)程是一個(gè)整合的過(guò)程,將不同業(yè)務(wù)系統(tǒng)的相同類(lèi)型的數(shù)據(jù)統(tǒng)一,比如同一個(gè)供應(yīng)商在結(jié)算系統(tǒng)的編碼是XX0001,而在CRM中編碼是YY0001,這樣在抽取過(guò)來(lái)之后統(tǒng)一轉(zhuǎn)換成一個(gè)編碼。
(2)數(shù)據(jù)粒度的轉(zhuǎn)換,業(yè)務(wù)系統(tǒng)一般存儲(chǔ)非常明細(xì)的數(shù)據(jù),而數(shù)據(jù)倉(cāng)庫(kù)中的數(shù)據(jù)是用來(lái)分析的,不需要非常明細(xì)的數(shù)據(jù),會(huì)將業(yè)務(wù)系統(tǒng)數(shù)據(jù)按照數(shù)據(jù)倉(cāng)庫(kù)粒度進(jìn)行聚合。一般數(shù)據(jù)轉(zhuǎn)換有離散化和屬性構(gòu)造兩種方式。離散化主要分為簡(jiǎn)單離散、分桶離散、聚類(lèi)離散、回歸平滑四類(lèi),屬性構(gòu)造分為特征工程和隨意構(gòu)造后篩選。
(3)商務(wù)規(guī)則的計(jì)算,不同的企業(yè)有不同的業(yè)務(wù)規(guī)則,不同的數(shù)據(jù)指標(biāo),這些指標(biāo)有的時(shí)候不是簡(jiǎn)單的加加減減就能完成,這個(gè)時(shí)候需要在ETL中將這些數(shù)據(jù)指標(biāo)計(jì)算好了之后存儲(chǔ)在數(shù)據(jù)倉(cāng)庫(kù)中,供分析使用。
4.ETL日志與警告發(fā)送
(1)ETL日志
記錄日志的目的是隨時(shí)可以知道ETL運(yùn)行情況,如果出錯(cuò)了,出錯(cuò)在那里。
ETL日志分為三類(lèi)。①執(zhí)行過(guò)程日志,是在ETL執(zhí)行過(guò)程中每執(zhí)行一步的記錄,記錄每次運(yùn)行每一步驟的起始時(shí)間,影響了多少行數(shù)據(jù),流水賬形式。②是錯(cuò)誤日志,當(dāng)某個(gè)模塊出錯(cuò)的時(shí)候需要寫(xiě)錯(cuò)誤日志,記錄每次出錯(cuò)的時(shí)間,出錯(cuò)的模塊以及出錯(cuò)的信息等。③日志是總體日志,只記錄ETL開(kāi)始時(shí)間,結(jié)束時(shí)間是否成功信息。
如果使用ETL工具,工具會(huì)自動(dòng)產(chǎn)生一些日志,這一類(lèi)日志也可以作為ETL日志的一部分。
(2)警告發(fā)送
ETL出錯(cuò)了,不僅要寫(xiě)ETL出錯(cuò)日志而且要向系統(tǒng)管理員發(fā)送警告,發(fā)送警告的方式有多種,常用的就是給系統(tǒng)管理員發(fā)送郵件,并附上錯(cuò)誤信息,便于管理員排查。
06、小結(jié)
在這里涉及到ETL中,我們只要有一個(gè)清晰的認(rèn)識(shí),它不是想象中的簡(jiǎn)單一蹴而就,在實(shí)際的過(guò)程,你可以會(huì)遇到各種各樣的問(wèn)題,甚至是部門(mén)之間溝通的問(wèn)題。出現(xiàn)以上問(wèn)題時(shí),可以和團(tuán)隊(duì)小伙伴或者業(yè)務(wù)側(cè)一起制定解決方案,不斷完善,只有這樣才能保證我們的業(yè)務(wù)分析結(jié)果是準(zhǔn)確的,才能指導(dǎo)公司做出正確的決策。
于是,企業(yè)如何通過(guò)各種技術(shù)手段,并把數(shù)據(jù)轉(zhuǎn)換為信息、知識(shí),已經(jīng)成了提高其核心競(jìng)爭(zhēng)力的關(guān)鍵,其中的數(shù)據(jù)處理在大數(shù)據(jù)的生態(tài)中始終處于不可缺少的地位,因?yàn)閿?shù)據(jù)處理的時(shí)效性,準(zhǔn)確性直接影響數(shù)據(jù)的分析與挖掘,分析的最終結(jié)果影響業(yè)務(wù)的營(yíng)銷(xiāo)與收入。
今天我們就來(lái)說(shuō)說(shuō)一種重要的數(shù)據(jù)處理手段ETL(Extract-Transform-Load)。
01、ETL發(fā)展的歷史背景
隨著企業(yè)的發(fā)展,各業(yè)務(wù)線、產(chǎn)品線、部門(mén)都會(huì)承建各種信息化系統(tǒng)方便開(kāi)展自己的業(yè)務(wù)。隨著信息化建設(shè)的不斷深入,由于業(yè)務(wù)系統(tǒng)之間各自為政、相互獨(dú)立造成的數(shù)據(jù)孤島”現(xiàn)象尤為普遍,業(yè)務(wù)不集成、流程不互通、數(shù)據(jù)不共享。這給企業(yè)進(jìn)行數(shù)據(jù)的分析利用、報(bào)表開(kāi)發(fā)、分析挖掘等帶來(lái)了巨大困難。
在此情況下,為了實(shí)現(xiàn)企業(yè)全局?jǐn)?shù)據(jù)的系統(tǒng)化運(yùn)作管理(信息孤島、數(shù)據(jù)統(tǒng)計(jì)、數(shù)據(jù)分析、數(shù)據(jù)挖掘) ,為DSS(決策支持系統(tǒng))、BI(商務(wù)智能)、經(jīng)營(yíng)分析系統(tǒng)等深度開(kāi)發(fā)應(yīng)用奠定基礎(chǔ),挖掘數(shù)據(jù)價(jià)值 ,企業(yè)會(huì)開(kāi)始著手建立數(shù)據(jù)倉(cāng)庫(kù),數(shù)據(jù)中臺(tái)。將相互分離的業(yè)務(wù)系統(tǒng)的數(shù)據(jù)源整合在一起,建立一個(gè)統(tǒng)一的數(shù)據(jù)采集、處理、存儲(chǔ)、分發(fā)、共享中心,從而使公司的成員能夠從不同業(yè)務(wù)部門(mén)查看綜合數(shù)據(jù),而這個(gè)過(guò)程中使用的數(shù)據(jù)處理方法之一就是ETL。
ETL是數(shù)據(jù)中心建設(shè)、BI分析項(xiàng)目中不可或缺的環(huán)節(jié)。各個(gè)業(yè)務(wù)系統(tǒng)中分布的、異構(gòu)的數(shù)據(jù)源,經(jīng)過(guò)ETL過(guò)程的數(shù)據(jù)抽取、轉(zhuǎn)換,最終存儲(chǔ)到目標(biāo)數(shù)據(jù)庫(kù)或者數(shù)據(jù)倉(cāng)庫(kù),為上層BI數(shù)據(jù)分析,或其他業(yè)務(wù)功能做數(shù)據(jù)支撐。
02、什么是ETL?
ETL,Extract-Transform-Load的縮寫(xiě),是將業(yè)務(wù)系統(tǒng)的數(shù)據(jù)經(jīng)過(guò)抽取、清洗轉(zhuǎn)換之后加載到數(shù)據(jù)倉(cāng)庫(kù)的過(guò)程。ETL是數(shù)據(jù)集成的第一步,也是構(gòu)建數(shù)據(jù)倉(cāng)庫(kù)最重要的步驟,目的是將企業(yè)中的分散、零亂、標(biāo)準(zhǔn)不統(tǒng)一的數(shù)據(jù)整合到一起,為企業(yè)的決策提供分析依據(jù)。ETL一詞較常用在數(shù)據(jù)倉(cāng)庫(kù),但其對(duì)象并不限于數(shù)據(jù)倉(cāng)庫(kù)。
舉個(gè)例子,某電商公司分析人員根據(jù)訂單數(shù)據(jù)進(jìn)行用戶特征分析。這時(shí)需要基于訂單數(shù)據(jù),計(jì)算一些相應(yīng)的分析指標(biāo),如每個(gè)用戶的消費(fèi)頻次,銷(xiāo)售額最大的單品,用戶復(fù)購(gòu)時(shí)間間隔等,這些指標(biāo)都要通過(guò)計(jì)算轉(zhuǎn)換得到。
03、ETL的流程
ETL如同它代表的三個(gè)英文單詞,涉及三個(gè)獨(dú)立的過(guò)程:抽取、轉(zhuǎn)換和加載。工作流程往往作為一個(gè)正在進(jìn)行的過(guò)程來(lái)實(shí)現(xiàn),各模塊可靈活進(jìn)行組合,形成ETL處理流程。
1.數(shù)據(jù)抽取
數(shù)據(jù)抽取指的是從不同的網(wǎng)絡(luò)、不同的操作平臺(tái)、不同的數(shù)據(jù)庫(kù)和數(shù)據(jù)格式、不同的應(yīng)用中抽取數(shù)據(jù)的過(guò)程。目標(biāo)源可能包括ERP、CRM和其他企業(yè)系統(tǒng),以及來(lái)自第三方源的數(shù)據(jù)。
不同的系統(tǒng)傾向于使用不同的數(shù)據(jù)格式,在這個(gè)過(guò)程中,首先需要結(jié)合業(yè)務(wù)需求確定抽取的字段,形成一張公共需求表頭,并且數(shù)據(jù)庫(kù)字段也應(yīng)與這些需求字段形成一一映射關(guān)系。這樣通過(guò)數(shù)據(jù)抽取所得到的數(shù)據(jù)都具有統(tǒng)一、規(guī)整的字段內(nèi)容,為后續(xù)的數(shù)據(jù)轉(zhuǎn)換和加載提供基礎(chǔ),具體步驟如下:
①確定數(shù)據(jù)源,需要確定從哪些源系統(tǒng)進(jìn)行數(shù)據(jù)抽取
②定義數(shù)據(jù)接口,對(duì)每個(gè)源文件及系統(tǒng)的每個(gè)字段進(jìn)行詳細(xì)說(shuō)明
③確定數(shù)據(jù)抽取的方法:是主動(dòng)抽取還是由源系統(tǒng)推送?是增量抽取還是全量抽取?是按照每日抽取還是按照每月抽取?
2.數(shù)據(jù)轉(zhuǎn)換
數(shù)據(jù)轉(zhuǎn)換實(shí)際上還包含了數(shù)據(jù)清洗的工作,需要根據(jù)業(yè)務(wù)規(guī)則對(duì)異常數(shù)據(jù)進(jìn)行清洗,主要將不完整數(shù)據(jù)、錯(cuò)誤數(shù)據(jù)、重復(fù)數(shù)據(jù)進(jìn)行處理,保證后續(xù)分析結(jié)果的準(zhǔn)確性。
數(shù)據(jù)轉(zhuǎn)換就是處理抽取上來(lái)的數(shù)據(jù)中存在的不一致的過(guò)程。數(shù)據(jù)轉(zhuǎn)換一般包括兩類(lèi):第一類(lèi):數(shù)據(jù)名稱(chēng)及格式的統(tǒng)一,即數(shù)據(jù)粒度轉(zhuǎn)換、商務(wù)規(guī)則計(jì)算以及統(tǒng)一的命名、數(shù)據(jù)格式、計(jì)量單位等;第二類(lèi):數(shù)據(jù)倉(cāng)庫(kù)中存在源數(shù)據(jù)庫(kù)中可能不存在的數(shù)據(jù),因此需要進(jìn)行字段的組合、分割或計(jì)算。主要涉及以下幾個(gè)方面:
①空值處理:可捕獲字段空值,進(jìn)行加載或替換為其他含義數(shù)據(jù),或數(shù)據(jù)分流問(wèn)題庫(kù)
②數(shù)據(jù)標(biāo)準(zhǔn):統(tǒng)一元數(shù)據(jù)、統(tǒng)一標(biāo)準(zhǔn)字段、統(tǒng)一字段類(lèi)型定義
③數(shù)據(jù)拆分:依據(jù)業(yè)務(wù)需求做數(shù)據(jù)拆分,如身份證號(hào),拆分區(qū)劃、出生日期、性別等
④數(shù)據(jù)驗(yàn)證:時(shí)間規(guī)則、業(yè)務(wù)規(guī)則、自定義規(guī)則
⑤數(shù)據(jù)替換:對(duì)于因業(yè)務(wù)因素,可實(shí)現(xiàn)無(wú)效數(shù)據(jù)、缺失數(shù)據(jù)的替換
⑥數(shù)據(jù)關(guān)聯(lián):關(guān)聯(lián)其他數(shù)據(jù)或數(shù)學(xué),保障數(shù)據(jù)完整性
3.數(shù)據(jù)加載
數(shù)據(jù)加載的主要任務(wù)是將經(jīng)過(guò)清洗后的干凈的數(shù)據(jù)集按照物理數(shù)據(jù)模型定義的表結(jié)構(gòu)裝入目標(biāo)數(shù)據(jù)倉(cāng)庫(kù)的數(shù)據(jù)表中,如果是全量方式則采用LOAD方式,如果是增量則根據(jù)業(yè)務(wù)規(guī)則MERGE進(jìn)數(shù)據(jù)庫(kù),并允許人工干預(yù),以及提供強(qiáng)大的錯(cuò)誤報(bào)告、系統(tǒng)日志、數(shù)據(jù)備份與恢復(fù)功能。整個(gè)操作過(guò)程往往要跨網(wǎng)絡(luò)、跨操作平臺(tái)。
在實(shí)際的工作中,數(shù)據(jù)加載需要結(jié)合使用的數(shù)據(jù)庫(kù)系統(tǒng)(Oracle、Mysql、Spark、Impala等),確定最優(yōu)的數(shù)據(jù)加載方案,節(jié)約CPU、硬盤(pán)IO和網(wǎng)絡(luò)傳輸資源。
04、ETL與ELT有什么區(qū)別?
ETL架構(gòu)按其字面含義理解就是按照E-T-L這個(gè)順序流程進(jìn)行處理的架構(gòu):先抽取、然后轉(zhuǎn)換、完成后加載到目標(biāo)數(shù)據(jù)庫(kù)中。
在ETL架構(gòu)中,數(shù)據(jù)的流向是從源數(shù)據(jù)流到ETL工具,ETL工具是一個(gè)單獨(dú)的數(shù)據(jù)處理引擎,一般會(huì)在單獨(dú)的硬件服務(wù)器上,實(shí)現(xiàn)所有數(shù)據(jù)轉(zhuǎn)化的工作,然后將數(shù)據(jù)加載到目標(biāo)數(shù)據(jù)倉(cāng)庫(kù)中。如果要增加整個(gè)ETL過(guò)程的效率,則只能增強(qiáng)ETL工具服務(wù)器的配置,優(yōu)化系統(tǒng)處理流程(一般可調(diào)的東西非常少)。
ELT架構(gòu)則把“L”這一步工作提前到“T”之前來(lái)完成:先抽取、然后加載到目標(biāo)數(shù)據(jù)庫(kù)中、在目標(biāo)數(shù)據(jù)庫(kù)中完成轉(zhuǎn)換操作。在ELT架構(gòu)中,ELT只負(fù)責(zé)提供圖形化的界面來(lái)設(shè)計(jì)業(yè)務(wù)規(guī)則,數(shù)據(jù)的整個(gè)加工過(guò)程都在目標(biāo)和源的數(shù)據(jù)庫(kù)之間流動(dòng),ELT協(xié)調(diào)相關(guān)的數(shù)據(jù)庫(kù)系統(tǒng)來(lái)執(zhí)行相關(guān)的應(yīng)用,數(shù)據(jù)加工過(guò)程既可以在源數(shù)據(jù)庫(kù)端執(zhí)行,也可以在目標(biāo)數(shù)據(jù)倉(cāng)庫(kù)端執(zhí)行(主要取決于系統(tǒng)的架構(gòu)設(shè)計(jì)和數(shù)據(jù)屬性)。當(dāng)ETL過(guò)程需要提高效率,則可以通過(guò)對(duì)相關(guān)數(shù)據(jù)庫(kù)進(jìn)行調(diào)優(yōu),或者改變執(zhí)行加工的服務(wù)器就可以達(dá)到。
ELT架構(gòu)的特殊優(yōu)勢(shì):①ELT主要通過(guò)數(shù)據(jù)庫(kù)引擎來(lái)實(shí)現(xiàn)系統(tǒng)的可擴(kuò)展性;②ELT可以保持所有的數(shù)據(jù)始終在數(shù)據(jù)庫(kù)當(dāng)中,避免數(shù)據(jù)的加載和導(dǎo)出,從而保證效率,提高系統(tǒng)的可監(jiān)控性;③ELT可以根據(jù)數(shù)據(jù)的分布情況進(jìn)行并行處理優(yōu)化,并可以利用數(shù)據(jù)庫(kù)的固有功能優(yōu)化磁盤(pán)I/O;④ELT的可擴(kuò)展性取決于數(shù)據(jù)庫(kù)引擎和其硬件服務(wù)器的可擴(kuò)展性;⑤通過(guò)對(duì)相關(guān)數(shù)據(jù)庫(kù)進(jìn)行性能調(diào)優(yōu),ELT過(guò)程獲得3到4倍的效率提升一般不是特別困難。
(1)當(dāng)您想要執(zhí)行復(fù)雜的計(jì)算時(shí),ETL工具比數(shù)據(jù)倉(cāng)庫(kù)或數(shù)據(jù)池更有效
(2)如果要在加載到目標(biāo)存儲(chǔ)之前進(jìn)行大量數(shù)據(jù)清理。ETL是一種更好的解決方案,因?yàn)槟粫?huì)將不需要的數(shù)據(jù)移動(dòng)到目標(biāo)。
(3)當(dāng)您僅使用結(jié)構(gòu)化數(shù)據(jù)或傳統(tǒng)結(jié)構(gòu)化數(shù)據(jù)倉(cāng)庫(kù)時(shí)。ETL工具通常最有效地將結(jié)構(gòu)化數(shù)據(jù)從一個(gè)環(huán)境移動(dòng)到另一個(gè)環(huán)境。
(4)當(dāng)你想要擴(kuò)展補(bǔ)充數(shù)據(jù)時(shí)。如果要在將數(shù)據(jù)移動(dòng)到目標(biāo)存儲(chǔ)時(shí)擴(kuò)展補(bǔ)充數(shù)據(jù),則需要使用ETL工具。例如,添加時(shí)間戳。
05、如何才能做好ETL?
1.數(shù)據(jù)抽取設(shè)計(jì)
數(shù)據(jù)的抽取需要在調(diào)研階段做大量工作,要搞清楚以下幾個(gè)問(wèn)題:數(shù)據(jù)是從幾個(gè)業(yè)務(wù)系統(tǒng)中來(lái)?各個(gè)業(yè)務(wù)系統(tǒng)的數(shù)據(jù)庫(kù)服務(wù)器運(yùn)行什么DBMS?是否存在手工數(shù)據(jù),手工數(shù)據(jù)量有多大?是否存在非結(jié)構(gòu)化的數(shù)據(jù)?等等類(lèi)似問(wèn)題,當(dāng)收集完這些信息之后進(jìn)行數(shù)據(jù)抽取的設(shè)計(jì)。常見(jiàn)的數(shù)據(jù)抽取設(shè)計(jì)方式有四種:
(1)與存放DW的數(shù)據(jù)庫(kù)系統(tǒng)相同的數(shù)據(jù)源處理方法
這一類(lèi)數(shù)源在設(shè)計(jì)比較容易,一般情況下,DBMS(包括SQLServer,Oracle)都會(huì)提供數(shù)據(jù)庫(kù)鏈接功能,在DW數(shù)據(jù)庫(kù)服務(wù)器和原業(yè)務(wù)系統(tǒng)之間建立直接的鏈接關(guān)系就可以寫(xiě)Select 語(yǔ)句直接訪問(wèn)。
(2)與DW數(shù)據(jù)庫(kù)系統(tǒng)不同的數(shù)據(jù)源的處理方法
這一類(lèi)數(shù)據(jù)源一般情況下也可以通過(guò)ODBC的方式建立數(shù)據(jù)庫(kù)鏈接,如SQL Server和Oracle之間。如果不能建立數(shù)據(jù)庫(kù)鏈接,可以有兩種方式完成,一種是通過(guò)工具將源數(shù)據(jù)導(dǎo)出成.txt或者是.xls文件,然后再將這些源系統(tǒng)文件導(dǎo)入到ODS中。另外一種方法通過(guò)程序接口來(lái)完成。
(3)對(duì)于文件類(lèi)型數(shù)據(jù)源(.txt,.xls)
可以培訓(xùn)業(yè)務(wù)人員利用數(shù)據(jù)庫(kù)工具將這些數(shù)據(jù)導(dǎo)入到指定的數(shù)據(jù)庫(kù),然后從指定的數(shù)據(jù)庫(kù)抽取。或者可以借助工具實(shí)現(xiàn),如SQL SERVER 2005 的SSIS服務(wù)的平面數(shù)據(jù)源和平面目標(biāo)等組件導(dǎo)入ODS中去。
(4)增量更新問(wèn)題
對(duì)于數(shù)據(jù)量大的系統(tǒng),必須考慮增量抽取。一般情況,業(yè)務(wù)系統(tǒng)會(huì)記錄業(yè)務(wù)發(fā)生的時(shí)間,可以用作增量的標(biāo)志,每次抽取之前首先判斷ODS中記錄最大的時(shí)間,然后根據(jù)這個(gè)時(shí)間去業(yè)務(wù)系統(tǒng)取大于這個(gè)時(shí)間的所有記錄。利用業(yè)務(wù)系統(tǒng)的時(shí)間戳,一般情況下,業(yè)務(wù)系統(tǒng)沒(méi)有或者部分有時(shí)間戳。
2.數(shù)據(jù)清洗處理規(guī)范
不符合要求的數(shù)據(jù)主要有不完成數(shù)據(jù)(缺失值)、錯(cuò)誤數(shù)據(jù)(異常值)、重復(fù)數(shù)據(jù)、不同類(lèi)型需歸一化處理數(shù)據(jù)幾類(lèi)。幾類(lèi)數(shù)據(jù)的處理方法如下:
缺失值:不完整的數(shù)據(jù),其特征是是一些應(yīng)該有的信息缺失,如供應(yīng)商的名稱(chēng),分公司的名稱(chēng),客戶的區(qū)域信息缺失、業(yè)務(wù)系統(tǒng)中主表與明細(xì)表不能匹配等。需要將這一類(lèi)數(shù)據(jù)過(guò)濾出來(lái),按缺失的內(nèi)容分別采取定(范圍)刪(字段)補(bǔ)(數(shù)據(jù))。
定范圍:哪些字段缺失,缺失范圍如何,缺失字段的重要性如何?刪字段:刪數(shù)據(jù)的判斷,a\對(duì)業(yè)務(wù)清晰的判斷,b\“有心殺賊,無(wú)力回天”缺失數(shù)據(jù)太多。這時(shí)候可以看看是否有其他數(shù)據(jù)可以彌補(bǔ)。補(bǔ)數(shù)據(jù):就是補(bǔ)充缺失值。這里有三種補(bǔ)數(shù)據(jù)的方式:A、業(yè)務(wù)知識(shí)驚訝填充;B、使用均值、中位數(shù)、眾數(shù)填充;C、使用其他渠道補(bǔ)充,如身份證前6位是地區(qū)=手機(jī)號(hào)歸屬地。補(bǔ)全后才寫(xiě)入數(shù)據(jù)倉(cāng)庫(kù)。
異常值:產(chǎn)生原因是業(yè)務(wù)系統(tǒng)不夠健全,在接收輸入后沒(méi)有進(jìn)行判斷直接寫(xiě)入后臺(tái)數(shù)據(jù)庫(kù)造成的,比如數(shù)值數(shù)據(jù)輸成全角數(shù)字字符、字符串?dāng)?shù)據(jù)后面有一個(gè)回車(chē)、日期格式不正確、日期越界等。這一類(lèi)數(shù)據(jù)也要分類(lèi),對(duì)于類(lèi)似于全角字符、數(shù)據(jù)前后有不面見(jiàn)字符的問(wèn)題只能寫(xiě)SQL的方式找出來(lái),然后要求客戶在業(yè)務(wù)系統(tǒng)修正之后抽取;日期格式不正確的或者是日期越界的這一類(lèi)錯(cuò)誤會(huì)導(dǎo)致ETL運(yùn)行失敗,這一類(lèi)錯(cuò)誤需要去業(yè)務(wù)系統(tǒng)數(shù)據(jù)庫(kù)用SQL的方式挑出來(lái),交給業(yè)務(wù)主管部門(mén)要求限期修正,修正之后再抽取。
重復(fù)數(shù)據(jù):特別是維表中比較常見(jiàn),將重復(fù)的數(shù)據(jù)的記錄所有字段導(dǎo)出來(lái),讓客戶確認(rèn)并整理。
數(shù)據(jù)歸一化:歸一化的問(wèn)題,就是將絕對(duì)數(shù)變成相對(duì)數(shù)的問(wèn)題。因?yàn)椴煌S度的絕對(duì)數(shù)是沒(méi)有可比性的,這時(shí)候需要將絕對(duì)數(shù)轉(zhuǎn)化成相對(duì)一個(gè)標(biāo)準(zhǔn)的相對(duì)數(shù)。那如何進(jìn)行歸一化處理呢?三種方式,A、最值歸一化、均值方差歸一化、非線性歸一化。
數(shù)據(jù)清洗是一個(gè)反復(fù)的過(guò)程,不可能在幾天內(nèi)完成,只有不斷的發(fā)現(xiàn)問(wèn)題,解決問(wèn)題。對(duì)于是否過(guò)濾、是否修正一般要求客戶確認(rèn);對(duì)于過(guò)濾掉的數(shù)據(jù),寫(xiě)入Excel文件或者將過(guò)濾數(shù)據(jù)寫(xiě)入數(shù)據(jù)表,在ETL開(kāi)發(fā)的初期可以每天向業(yè)務(wù)單位發(fā)送過(guò)濾數(shù)據(jù)的郵件,促使他們盡快的修正錯(cuò)誤,同時(shí)也可以作為將來(lái)驗(yàn)證數(shù)據(jù)的依據(jù)。數(shù)據(jù)清洗需要注意的是不要將有用的數(shù)據(jù)過(guò)濾掉了,對(duì)于每個(gè)過(guò)濾規(guī)則認(rèn)真進(jìn)行驗(yàn)證,并要用戶確認(rèn)才行。
3.數(shù)據(jù)轉(zhuǎn)換處理規(guī)范
數(shù)據(jù)轉(zhuǎn)換的任務(wù)主要是進(jìn)行不一致的數(shù)據(jù)轉(zhuǎn)換、數(shù)據(jù)粒度的轉(zhuǎn)換和一些商務(wù)規(guī)則的計(jì)算。
(1)不一致數(shù)據(jù)轉(zhuǎn)換,這個(gè)過(guò)程是一個(gè)整合的過(guò)程,將不同業(yè)務(wù)系統(tǒng)的相同類(lèi)型的數(shù)據(jù)統(tǒng)一,比如同一個(gè)供應(yīng)商在結(jié)算系統(tǒng)的編碼是XX0001,而在CRM中編碼是YY0001,這樣在抽取過(guò)來(lái)之后統(tǒng)一轉(zhuǎn)換成一個(gè)編碼。
(2)數(shù)據(jù)粒度的轉(zhuǎn)換,業(yè)務(wù)系統(tǒng)一般存儲(chǔ)非常明細(xì)的數(shù)據(jù),而數(shù)據(jù)倉(cāng)庫(kù)中的數(shù)據(jù)是用來(lái)分析的,不需要非常明細(xì)的數(shù)據(jù),會(huì)將業(yè)務(wù)系統(tǒng)數(shù)據(jù)按照數(shù)據(jù)倉(cāng)庫(kù)粒度進(jìn)行聚合。一般數(shù)據(jù)轉(zhuǎn)換有離散化和屬性構(gòu)造兩種方式。離散化主要分為簡(jiǎn)單離散、分桶離散、聚類(lèi)離散、回歸平滑四類(lèi),屬性構(gòu)造分為特征工程和隨意構(gòu)造后篩選。
(3)商務(wù)規(guī)則的計(jì)算,不同的企業(yè)有不同的業(yè)務(wù)規(guī)則,不同的數(shù)據(jù)指標(biāo),這些指標(biāo)有的時(shí)候不是簡(jiǎn)單的加加減減就能完成,這個(gè)時(shí)候需要在ETL中將這些數(shù)據(jù)指標(biāo)計(jì)算好了之后存儲(chǔ)在數(shù)據(jù)倉(cāng)庫(kù)中,供分析使用。
4.ETL日志與警告發(fā)送
(1)ETL日志
記錄日志的目的是隨時(shí)可以知道ETL運(yùn)行情況,如果出錯(cuò)了,出錯(cuò)在那里。
ETL日志分為三類(lèi)。①執(zhí)行過(guò)程日志,是在ETL執(zhí)行過(guò)程中每執(zhí)行一步的記錄,記錄每次運(yùn)行每一步驟的起始時(shí)間,影響了多少行數(shù)據(jù),流水賬形式。②是錯(cuò)誤日志,當(dāng)某個(gè)模塊出錯(cuò)的時(shí)候需要寫(xiě)錯(cuò)誤日志,記錄每次出錯(cuò)的時(shí)間,出錯(cuò)的模塊以及出錯(cuò)的信息等。③日志是總體日志,只記錄ETL開(kāi)始時(shí)間,結(jié)束時(shí)間是否成功信息。
如果使用ETL工具,工具會(huì)自動(dòng)產(chǎn)生一些日志,這一類(lèi)日志也可以作為ETL日志的一部分。
(2)警告發(fā)送
ETL出錯(cuò)了,不僅要寫(xiě)ETL出錯(cuò)日志而且要向系統(tǒng)管理員發(fā)送警告,發(fā)送警告的方式有多種,常用的就是給系統(tǒng)管理員發(fā)送郵件,并附上錯(cuò)誤信息,便于管理員排查。
06、小結(jié)
在這里涉及到ETL中,我們只要有一個(gè)清晰的認(rèn)識(shí),它不是想象中的簡(jiǎn)單一蹴而就,在實(shí)際的過(guò)程,你可以會(huì)遇到各種各樣的問(wèn)題,甚至是部門(mén)之間溝通的問(wèn)題。出現(xiàn)以上問(wèn)題時(shí),可以和團(tuán)隊(duì)小伙伴或者業(yè)務(wù)側(cè)一起制定解決方案,不斷完善,只有這樣才能保證我們的業(yè)務(wù)分析結(jié)果是準(zhǔn)確的,才能指導(dǎo)公司做出正確的決策。 (部分內(nèi)容來(lái)源網(wǎng)絡(luò),如有侵權(quán)請(qǐng)聯(lián)系刪除)
立即免費(fèi)申請(qǐng)產(chǎn)品試用
免費(fèi)試用
相關(guān)文章推薦
-
據(jù)分析助力企業(yè)決策與業(yè)務(wù)創(chuàng)新")
用數(shù)據(jù)分析助力企業(yè)決策與業(yè)務(wù)創(chuàng)新
發(fā)布時(shí)間:2023-09-26瀏覽量:103次
在數(shù)字化時(shí)代,數(shù)據(jù)分析已經(jīng)成為企業(yè)成功的關(guān)鍵因素之一。作為國(guó)內(nèi)領(lǐng)先的數(shù)據(jù)分析廠商,億信華辰一直致力于為各類(lèi)企業(yè)提供最優(yōu)質(zhì)的數(shù)據(jù)分析產(chǎn)品和...查看詳情 -
習(xí)數(shù)據(jù)分析?數(shù)據(jù)分析產(chǎn)出是什么?")
為什么要學(xué)習(xí)數(shù)據(jù)分析?數(shù)據(jù)分析產(chǎn)出是什么?
發(fā)布時(shí)間:2022-06-28瀏覽量:1052次
「過(guò)去」以往在增量時(shí)代,每天都有新的領(lǐng)域、新的市場(chǎng)被開(kāi)發(fā)。尤其是在互聯(lián)網(wǎng)、電商等領(lǐng)域的紅利期,似乎只要做好單點(diǎn)的突破就能獲得市場(chǎng)。這個(gè)蠻...查看詳情 -
據(jù)分析很痛苦?5個(gè)對(duì)策、8大方法幫到你!")
數(shù)據(jù)分析很痛苦?5個(gè)對(duì)策、8大方法幫到你!
發(fā)布時(shí)間:2022-06-15瀏覽量:284次
“對(duì)數(shù)據(jù)敏感,能夠通過(guò)數(shù)據(jù)分析與反饋,不斷改進(jìn)和優(yōu)化產(chǎn)品”之類(lèi)的招聘要求屢見(jiàn)不鮮。誠(chéng)然,數(shù)據(jù)分析能力已經(jīng)成為產(chǎn)品經(jīng)理不可或缺的技能。數(shù)據(jù)...查看詳情 -
據(jù)的過(guò)去、現(xiàn)在和未來(lái)")
淺談大數(shù)據(jù)的過(guò)去、現(xiàn)在和未來(lái)
發(fā)布時(shí)間:2022-06-14瀏覽量:576次
相信身處于大數(shù)據(jù)領(lǐng)域的讀者多少都能感受到,大數(shù)據(jù)技術(shù)的應(yīng)用場(chǎng)景正在發(fā)生影響深遠(yuǎn)的變化: 隨著實(shí)時(shí)計(jì)算、Kubernetes 的崛起和 HTAP、流批一體...查看詳情 -
字經(jīng)濟(jì)時(shí)代,企業(yè)的核心競(jìng)爭(zhēng)力究竟是什么?")
數(shù)字經(jīng)濟(jì)時(shí)代,企業(yè)的核心競(jìng)爭(zhēng)力究竟是什么?
發(fā)布時(shí)間:2022-06-14瀏覽量:801次
數(shù)字經(jīng)濟(jì)時(shí)代對(duì)于企業(yè)而言意味著全新的挑戰(zhàn)和機(jī)遇,如何抓住數(shù)字經(jīng)濟(jì)的本質(zhì),而不是停留在各種零碎的、華麗的詞藻堆砌,構(gòu)建企業(yè)核心競(jìng)爭(zhēng)力新的理...查看詳情
相關(guān)主題
相關(guān)產(chǎn)品推薦更多
-
服務(wù)方式
400咨詢:4000011866
手機(jī)咨詢:137-0121-6791技術(shù)支持QQ:400-0011-866
(工作日9:00-18:00)產(chǎn)品建議郵箱
yixin@esensoft.com -
關(guān)注我們

版權(quán)所有? 2006-2025 北京億信華辰軟件有限責(zé)任公司
京ICP備07017321號(hào) 京公網(wǎng)安備11010802016281號(hào)免責(zé)聲明
